因為最近的工作需求,我開始學習與補強系統效能分析方面的知識。所以我把同事之前推薦的論文 The Case of the Missing Supercomputer Performance [Fabrizio Petrini et al. 2003] 拿出來仔細研究。
摘要
這篇論文提出一個重要觀察:背景程式(Daemon)的干擾有時會嚴重影響特定負載(Workload)的執行速度。如果能妥善處理這些干擾,有機會可以讓總執行時間減半。
這個結論在當時是非常特別的。因為在分析程式效能的時候,直覺的作法是專注分析「程式本身」的問題。有時候會從理論分析演算法或計算流程有沒有改善空間。有時是對程式做 Profiling,尋找有沒有明顯的熱區或者效能瓶頸。有時是改進編譯器,讓編譯器可以產生比較好的機器碼。然而這些作法背後都隱含一個假設:執行程式時,這個程式可以完全享有整個系統的計算資源。這對現代「分時多工的計算系統」而言是不成立的。
論文舉出需要「Fine-Grained Synchronization」的負載特別容易被背景程式影響。以下是用 OpenMP 編寫的示意程式碼:
for (int T = 0; T < NUM_ITERATIONS; ++T) {
#pragma omp parallel for
for (int i = 0; i < dimension; ++i) {
data[(T + 1) % 2][i] = compute(data[T % 2], i);
}
}
這個程式主要是由一個外圍的迴圈迭代若干次,每次計算都依賴前一次迭代的計算結果。中間的 #pragma omp parallel for 會把內層的迴圈分散到不同的處理單元。內層迴圈執行完畢後,會有一個 Implicit Barrier 同步計算結果,確保所有的處理單元都能看到其他處理單元的計算結果。
如果把處理單元當作縱軸、外層迴圈的迭代當成橫軸,執行計算的過程以藍色橫條表示,大約可以畫出以下示意圖:
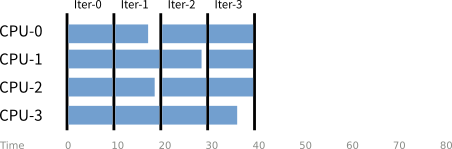
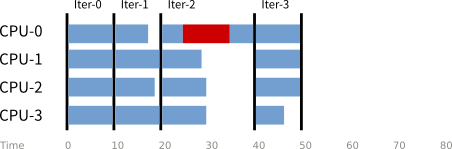
然而上圖只是理想情況。實際上因為「分時多工」的特性,有時候部分處理單元必須暫定計算工作執行背景程式。如果以紅色畫出些背景工作,可以畫出以下示意圖:
論文當中的超級電腦 ASCI Q 一開始有 2048 個處理單元,最後會有 8192 個處理單元。這大幅提高「單一迭代中有一個處理單元在執行背景工作」的機率。在極端情況下,每個迭代都可能遇上一次中斷,使得總體時間變成理想情況的兩倍(如下圖所示):
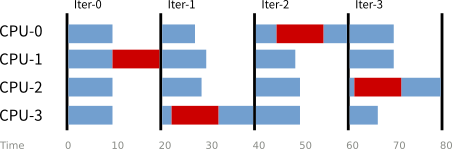
附帶一提,這個例子也點出「系統層級效能分析」的重要性。因為大多數的處理器都是在等待狀態,即使加快負載本身的執行速度,能減少的等待時間還是很有限。
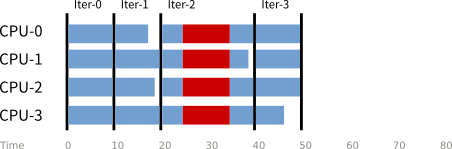
經過若干實驗分析(包含關閉非必要的背景程式、減少背景程式的觸發頻率等等),論文作者證實這些背景程式確實是「實際效能」和「預測效能」落差的主因。但是部分背景程式是系統必備的工具,所以作者最後提出修改 Linux 核心排程器的構想。具體的作法是讓所有的處理單元可以在同一個時間執行背景程式,進而達成以下示意圖:
評論
我常覺得系統效能分析是一門帶有藝術色彩的科學。本文前面的摘要是直接從論文的結論寫起。然而這篇論文的結構比較像是一篇偵探小說。一開始論文的作者們只知道「實際效能」與「預測效能」有明顯落差。作者們也嘗試過一些最佳化,但效用都不大。最關鍵的線索是:雖然每個節點有 4 個處理器,但是如果只使用 3 個處理器執行負載,總體而言可以跑得比較快(相對於使用 4 個處理器)。我覺得這個線索帶有一些藝術成份。一開始作者們是怎麼發現的呢?是直接把所有可以調整的參數試試看嗎?還是剛好意外發現這個違反直覺的結果?然而,在論文中,這個線索只用一句「Battery Testing」帶過,我覺得是有一點可惜的。
除了這個線索之外,這篇論文就是紮實的「推理—假說—實驗—論證」的過程。作為讀者,我們可以知道作者們是如何排除次要因素,也可以知道作者們如何再次考慮本來忽略的因素。討論過程的重要性不亞於最後的結論。畢竟每個人遇到的情境不同,問題的根源也會有些許差異。
最後,這篇論文點出的系統層級效能分析是讓我印象最深刻的結論。也讓我意識到分析一個計算系統的總體效能不能只看一個負載在單獨執行能跑多快。很多時候,輸入輸出、硬體中斷、甚至是本論文發現的背景程式都有可能嚴重的影響效能。在分析「程式為什麼跑不快」的時候要有更全面的思考。




