在最佳化程式之前,我們必須要先測量程式的執行狀況,如此我們才能對症下藥。本文要介紹 Linux 核心內建的系統效能分析工具——perf_events。
perf_events
perf_events 是 Linux 核心內建的系統效能分析工具。perf_events 一開始的主要功能是存取硬體效能計數器,所以最早的名字是 Performance Counters for Linux (PCL)。隨著功能不斷擴充,perf_events 能處理的事件來源已經不限於硬體效能計數器,所以改名為 perf_events。
有時候 perf_events 也被簡稱為 Perf。然而因為 Perf 作為一個單字是難以搜尋的常見字𢑥,所以 Vince Weaver 與 Brendan Gregg 前輩通常使用 perf_events 稱呼這套工具。
perf_events 這套工具分為三個部分:
- 在 User Space 的
perf指令 - 在 Kernel Space 負責處理和儲存事件記錄的機制
- 在 Kernel Space 的事件來源:硬體效能計數器、中斷、Page Fault、系統呼叫、KProbe、UProbe、FTrace、Trace Point 等等。
如果負載大多數時間都在執行狀態(CPU-bound 負載),最常使用的事件來源是硬體效能計數器。如果負載要花不少時間從硬碟或網路讀寫資料(IO-bound 負載)或者是要和其他負載共用特定資源(例如:Mutex、Semaphore 等),則建議改用 FTrace、Trace Point、KProbe 與 UProbe 等事件來源。
本文會先著重於硬體效能計數器,其他功能會再另外為文介紹。
取樣測量
取樣測量的基本概念就是透過記錄下來的樣本回推程式的真實狀況。以下圖為例,假設上方的長條圖是各個函式的執行時間,下方的五邊型是取樣記錄。圖中,分別以 1 Hz 與 2 Hz 的頻率取樣。我們可以從樣本的比例,大約知道 25% 的時間是花費在橘色函式,75% 的時間是花費在藍色函式。

取樣測量最大的優點就是測量過程的額外負擔可以透過取樣頻率調整。使用者可以選用適當的取樣頻率,降低觀察者效應的影響,進而減少測量誤差。如果想要測量的事件數量超過一定的數量級,又沒有外部裝置能記錄事件,通常就只能探用取樣測量。
取樣測量的準確度主要受二個因素影響:樣本的代表性與樣本的數量。
樣本的代表性可以再分為二個層面:樣本是否均勻的分散在總體執行時間、取樣頻率是否會剛好和觀察對象本身的週期同調(Lockstep)。關於前者,Linux 核心的預設行為就是儘可能均勻地取樣,所以使用者不用太擔心。後者則能透過指定不同的目標頻率來減少發生的機會。常用的頻率是 97、997、9973 等質數。
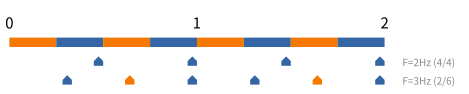
從樣本數量來看,取樣頻率頻率的高低也會影響精準度。一般而言,取樣頻率要比「重要事件的發生頻率」還高才能從樣本觀察到這個重要事件。然而取樣率越高,額外負擔也越高,觀察者效應也越顯著,所以我們必須選定一個適當的頻率。
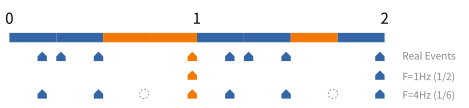
以下圖為例,假設第 1 列是所有發生過的事件。第 2 列是頻率為 1 Hz 的樣本。第 3 列是頻率為 4 Hz 的樣本,其中空心圈代表該時段沒有樣本。如果只看第 2 列,我們會誤以為事件均勻地分部於橘色與藍色函式。然而,第 3 列告訴我們橘色函式產生的事件並不多。大多數的事件是藍色函式產生的。
另外,受限於實作,perf_events 的取樣頻率的上限大約是 10,000 Hz(數量級)。這個數值可以透過 /proc/sys/kernel/perf_event_max_sample_rate 修改。但是如果 Linux 核心在取樣過程中發現整個系統無法支撐指定的取樣頻率,Linux 核心會自動降低取樣頻率。
取樣測量也有它的缺點。其中一個是取樣測量通常以執行時間作為母體。所以比較不容易觀察到輸入輸出或同步造成的效能問題。其二是取樣測量的基本理論是以統計樣本次數回推真實的行為,我們難以從樣本回推真實各種事件的順序。如果效能問題和事件發生的順序有關,取樣測量比較沒有辦法告訴我們問題的來源。雖然有上述問題,取樣測量還是很好的效能測量方法。它的低額外負擔和可以指定取樣頻率還是讓它成為效能測量的首選。
硬體效能計數器
許多 CPU 會內建效能監控單元(Performance Monitoring Unit)有時候簡記為 PMU。它能提供 Cycles、Instructions Retired、Cache Misses、L1 I-Cache Load Misses、L1 D-Cache Load Misses、Last Level Cache Misses 等重要資訊。
因為一般的手機或桌上型電腦 CPU 的時脈大約是 1.8-2.3 GHz,事件發生的頻率可能也是以 GHz 為單位,所以 CPU 內建的 PMU 通常是若干個效能計數器(Performance Counter)取樣指定事件。在開始測量效能前,使用者(或作業系統)可以為每個效能計數器設定一個週期(Period)。在測量過程中,每當指定事件發生時,效能計數器就會減 1。當效能計數器減到 0 的時候,效能計數器就會觸發中斷,然後作業系統的中斷處理程序就會記錄當時的狀況。
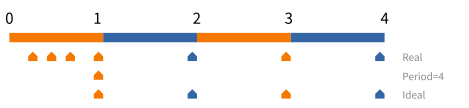
雖然從硬體設計的角度來看,以週期取樣比較容易實作,然而對於使用者而言,將取樣點平均分散在整個程式的執行時間是較常使用的取樣方式。以下圖的極端例子舉例,如果週期固定是 4,只有第 1 個時間間隔會有樣本。比較理想的方式是將取樣點分散在 4 個時間間隔。
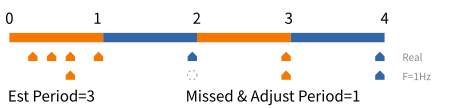
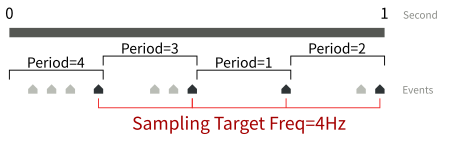
perf_events 可以讓使用者以一個目標頻率(Frequency)取樣指定事件。他的實作原理是讓 Linux 核心自動地調整週期。如果上個時間間隔內有太多事件樣本,則提高週期;反之,如果上個時間間隔內的事件樣本過少,則減少週期。以下圖為例,假設以 1 Hz 為目標頻率,perf_events 可能會先假設週期為 3,並在第 1 個時間間隔取得一個樣本。然而在第 2 秒結束時,perf_events 會發現它錯過一個樣本,因此將週期下調為 1。下調週期後,第 3 與 4 時間間隔就能順利取得樣本。
附帶一提,筆者一開始看到週期和頻率的時候非常困惑。因為在物理學中,一個波的週期(每次需要多少秒)和頻率(每秒需要多少次)互為倒數。然而 perf_events 這套工具內,它們分別指稱不同的東西:
- 週期指的是從「開始」到「記錄樣本」之間,事件的發生次數。
- 目標頻率指的是
perf_events每秒應該要剛好取得多少樣本。
週期與目標頻率的關係如下圖所示。灰色為所有發生過的事件。黑色為記錄到的事件樣本(共 4 個)。因為目標週期為 4 Hz,所以 perf_events 每 0.25 秒可以設定不同的週期。下圖的週期依序為 4 個、3 個、1 個、2 個事件。
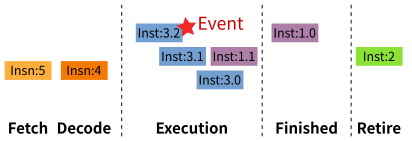
另外,效能計數器的統計次數有時候會落在「觸發事件的指令」的後方。稍後的例子中,有些 L1 Data Cache Miss 會被記錄在 add 與 cmp 二個只使用暫存器的指令上。這個現象在 Intel 技術文件中被稱為 Skid(滑行)。以開車類比,就像是踩下煞車後,車子還會滑行一小段距離。這是因為高速 CPU 通常都有比較多層的 Pipeline、一個指令通常會再拆分為多個 Micro-Ops(微指令)、再加上 Out-of-Order Execution (亂序執行)會先執行準備就緒的 Micro-Ops,CPU 要準確地追蹤「觸發事件的指令」要花費不少成本(下圖為示意圖),因此部分事件會被記錄在稍後的指令。使用者在解讀事件數量的時候,務必要考慮 Skid 現象。
最後,效能計數器的數量是有限的。部分效能計數器有時會有指定用途,使得通用效能計數器(General-purpose Performance Counter)又更少了。如果同時測量過多的事件種類,Linux 會以分時多工的方式共用同一個效能計數器。因為這會稍微影響精確度,所以應盡可能減少非必要的事件種類。
準備工作
本文後半部會介紹如何使用 perf_events 找出簡單矩陣乘法的問題。但在此之前,我們必需先安裝 perf 指令並取得一些重要的參考資料。
安裝
在 Debian 上,執行以下指令安裝 perf 指令:
$ sudo apt-get install linux-perf
在 Ubuntu 上,執行以下指令安裝 perf 指令:
$ sudo apt-get install \
linux-tools-generic linux-tools-$(uname -r)
備註:perf 指令會隨著 Linux 核心版本而有所變動,所以上面的指令同時安裝了 linux-tools-generic 與 linux-tools-$(uname -r)。其中的 $(uname -r) 會被代換為使用中的 Linux 核心版本。如果你更新了 Ubuntu 的 Linux 核心,perf 指令可能會印出以下錯誤訊息。重新執行以上指令即可解決問題。
$ sudo perf
WARNING: perf not found for kernel 4.18.0-25
You may need to install the following packages for this
specific kernel:
linux-tools-4.18.0-25-generic
linux-cloud-tools-4.18.0-25-generic
You may also want to install one of the following packages to
keep up to date:
linux-tools-generic
linux-cloud-tools-generic
程式碼
perf_events 一直有很多改動,因此相關資料一直不是很齊全。有時說明文件還會和最新版的 perf_events 有細微差異。所以如果使用 perf_events 的過程中遇上任何問題,最終還是要從程式碼尋找答案。perf_events 的程式碼存放於 Linux 核心的 Git 版本庫。你可以使用以下指令取得所有程式碼與開發記錄:
$ git clone git://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git
以下列出幾個重點檔案與資料夾:
- tools/perf 包含
perf指令的程式碼與說明文件。 - tools/perf/design.txt 包含
perf指令與 Linux 核心之間的介面。 - kernel/events 包含
perf_events的框架。可以在這裡找到 Linux 核心怎麼取樣事件、怎麼處理記錄。 - kernel/trace 包含 Linux 追蹤框架的實作。
- include/trace 包含 Linux 追蹤框架的標頭檔案。
- include/uapi/linux/perf_event.h 包含許多
perf_events常數。 - arch/x86/events/intel 包含 Intel CPU 的效能計數器實作。另外,也能在這個目錄找到「事件名稱」和「硬體事件編號」的對應表,以便查尋 Intel 的處埋器架構手冊。
- arch/x86/events/amd 包含 AMD CPU 的效能計數器實作。
- arch/arm64/kernel/perf_event.c 包含 AArch64 CPU 的效能計數器實作。
處理器架構手冊
效能計數器大多和 CPU 的設計緊密結合,每個產品線或微架構常會有細微的差異。因此手邊有一份處理器架構手冊便是很重要的事。以下僅列出一些常見 CPU 的處理器架構手冊:
- Intel x86
- Intel 64 and IA-32 Architectures Software Developer Manuals 第三部第 18 章 Performance Monitoring 與第 19 章 Performance Monitoring Events
- Intel Processor Event Reference
- AMD x86-64
- AMD64 Architecture Programmer's Manual Volume 2: System Programming 第 17 章 Hardware Performance Monitoring and
- ARM AArch64
- Armv8-M Architecture Reference Manual 第 B14 章 The Performance Monitoring Unit Extension Control
常用指令概覽
perf 指令有很多子指令(Sub-command)。本文只會涵蓋以下 4 個重要指令:
| 指令 | 說明 |
|---|---|
perf list |
列出 Linux 核心與硬體支援的事件種 類。 |
perf stat [-e [events]] [cmd] |
執行指定程式。執行結束後,印出各 事件的總體統計數據。
|
perf record [-e [events]] [-g] [cmd] |
執行指定程式。執行過程中,取樣並記 錄各事件。這個指令能讓我們能大略 知道事件的發生地點。
|
perf report [-g graph,0.5,caller] |
讀取
|
備註:若測量對象沒有安全疑慮,以上所有指令都建議使用 sudo 執行。
測量矩陣相乘程式效能
作為範例,我寫了一個簡單的矩陣相乘程式 matrix-v1.c:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <stdint.h>
#define N 1024
#define NUM_ROUNDS 5
static int32_t a[N][N];
static int32_t b[N][N];
static int32_t c[N][N];
__attribute__((noinline))
static void load_matrix() {
FILE *fp = fopen("input.dat", "rb");
if (!fp) {
abort();
}
if (fread(a, sizeof(a), 1, fp) != 1) {
abort();
}
if (fread(b, sizeof(b), 1, fp) != 1) {
abort();
}
fclose(fp);
}
__attribute__((noinline))
static void mult() {
size_t i, j, k;
for (i = 0; i < N; ++i) {
for (j = 0; j < N; ++j) {
for (k = 0; k < N; ++k) {
c[i][j] += a[i][k] * b[k][j];
}
}
}
}
__attribute__((always_inline))
static inline void escape(void *p) {
__asm__ volatile ("" : : "r"(p) : "memory");
}
int main() {
int r;
load_matrix();
for (r = 0; r < NUM_ROUNDS; ++r) {
memset(c, '\0', sizeof(c));
escape(c);
mult();
escape(c);
}
return 0;
}
這個程式會從 input.dat 讀取 2 個 1024 * 1024 的 int32_t 矩陣。接著會執行 5 次 mult 函式。
為了方便觀察,這個範例程式有一些平常寫程式不會用到的東西,筆者分述如下:
__attribute__((noinline))確保編譯器在最佳化模式下也不會把load_matrix與mult函式 Inline 進main函式。__attribute__((always_inline))確保編譯器一定會把escape函式 Inline 進main函式。escape函式裡面只有一行 Inline Assembly。它確保編譯器不會把一些「結果沒被用到的計算」視為 Dead Code(死碼)。這是 Chandler Carruth 於 CppCon 2015 介紹的技巧。這在編寫 Micro Benchmark 的時候很實用。
當然,一般測量程式效能的時候不會刻意加這些程式碼。不過作為範例,它們能簡化實驗結果。
第一步:編譯 matrix-v1.c:
$ gcc matrix-v1.c -o matrix-v1 -Wall -O2 -g -fno-omit-frame-pointer
注意:這裡我指定了 -O2 最佳化層級。一般測量程式效能應儘量使用最佳化過後的執行檔。唯一的例外是 -fno-omit-frame-pointer。這個選項能讓 perf_events 簡單地記錄 Stack Trace。雖然 -fno-omit-frame-pointer 會稍微降低程式本身的效能,但和其他方法相比,這是一個比較平衡的選項。最後,我還指定 -g 以產生除錯資訊,方便 perf 指令標注蒐集的資料。
第二步:產生矩陣測試資料:
$ dd if=/dev/urandom of=input.dat bs=$((8 * 1024 * 1024)) count=1
第三步:以 perf stat 取得總體統計數據:
$ sudo perf stat ./matrix-v1
# started on Tue Jul 9 21:51:05 2019
Performance counter stats for './matrix-v1':
22880.679285 task-clock (msec) # 0.996 CPUs utilized
982 context-switches # 0.043 K/sec
2 cpu-migrations # 0.000 K/sec
3,120 page-faults # 0.136 K/sec
43,477,093,326 cycles # 1.900 GHz
37,665,611,985 instructions # 0.87 insn per cycle
5,381,372,120 branches # 235.193 M/sec
5,517,347 branch-misses # 0.10% of all branches
22.962599044 seconds time elapsed
22.870927000 seconds user
0.011980000 seconds sys
perf stat 提供的數據中,Insn Per Cycle 指標看起來有問題。現代 CPU 一個 Cycle 通常能完成多個指令,低於 1 絕對不正常。但目前為止我們還不知道為什麼。我們需要更多資訊。
第四步:以 perf record -g 取樣:
$ sudo perf record -g ./matrix-v1
第五步:以 perf report 讀取報告:
$ sudo perf report -g graph,0.5,caller
首先會看到以下畫面:
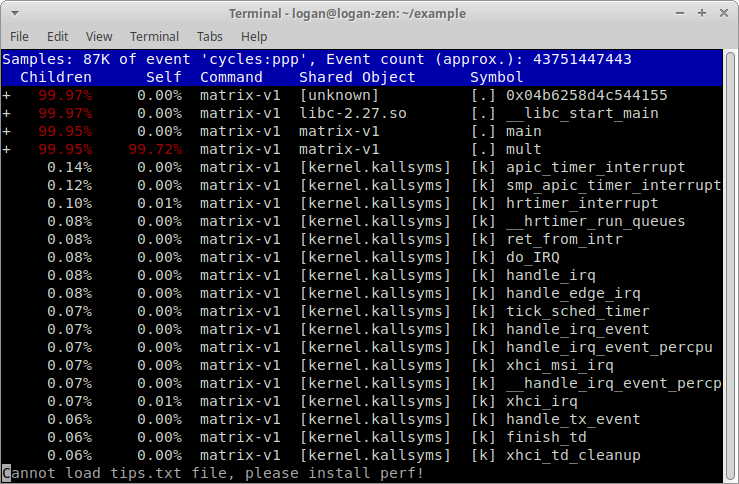
看到 mult 函式花去最多時間後,將游標以「向下鍵」移至 mult,按下按鍵 a,接著會顯示以下畫面:
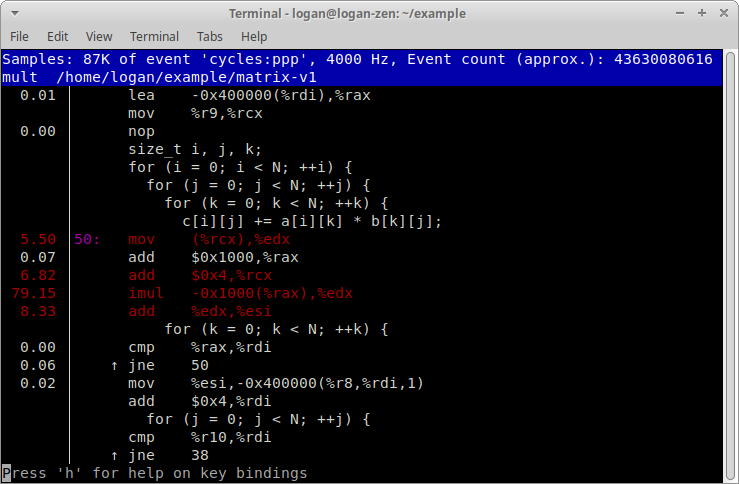
因為 imul (與之後兩個指令)花的時間特別久。imul 的 -0x1000(%rax) 運算元會把矩陣 b 的資料搬進 CPU。我懷疑資料無法即時送給 CPU,但是我現在還沒有足夠的證據,所以我接著使用 perf list 尋找合適的事件種類。
第六步:以 perf list 查詢合適的事件種類:
$ sudo perf list
List of pre-defined events (to be used in -e):
branch-instructions OR branches [Hardware event]
branch-misses [Hardware event]
bus-cycles [Hardware event]
cache-misses [Hardware event]
cache-references [Hardware event]
cpu-cycles OR cycles [Hardware event]
instructions [Hardware event]
ref-cycles [Hardware event]
... 中略 ...
L1-dcache-load-misses [Hardware cache event]
L1-dcache-loads [Hardware cache event]
L1-dcache-stores [Hardware cache event]
L1-icache-load-misses [Hardware cache event]
LLC-load-misses [Hardware cache event]
LLC-loads [Hardware cache event]
LLC-store-misses [Hardware cache event]
LLC-stores [Hardware cache event]
從列表中,我看到 L1-dcache-load-misses 好像符合我的需求,下次執行 perf record 的時候把它加進測量清單。
第七步:重新使用 perf record 記錄 caches、instructions 與 L1-dcache-load-miss 的事件次數:
$ sudo perf record -g \
-e cycles,instructions,L1-dcache-load-misses \
./matrix-v1
第八步:再次以 perf report 讀取報告:
$ sudo perf report -g graph,0.5,caller
因為我同時測量了 3 個事件種類,這次 perf report 要我先選擇事件種類(以「向上下鍵」移動和「Enter 鍵」選擇):
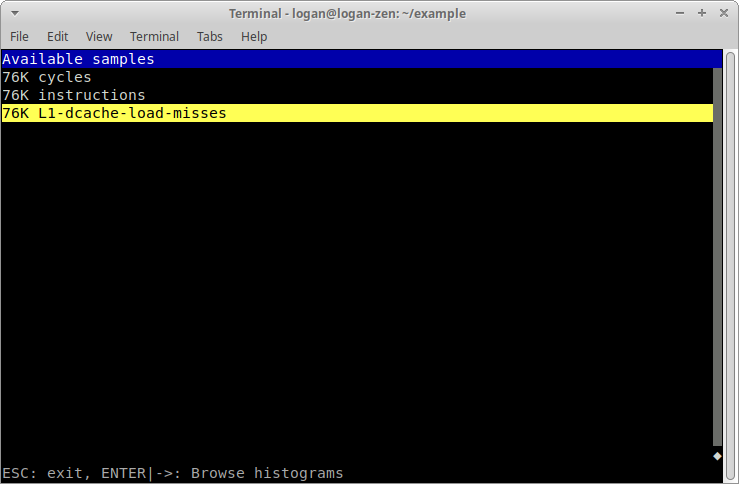
接著,將游標以「向下鍵」移至 mult,按下按鍵 a:
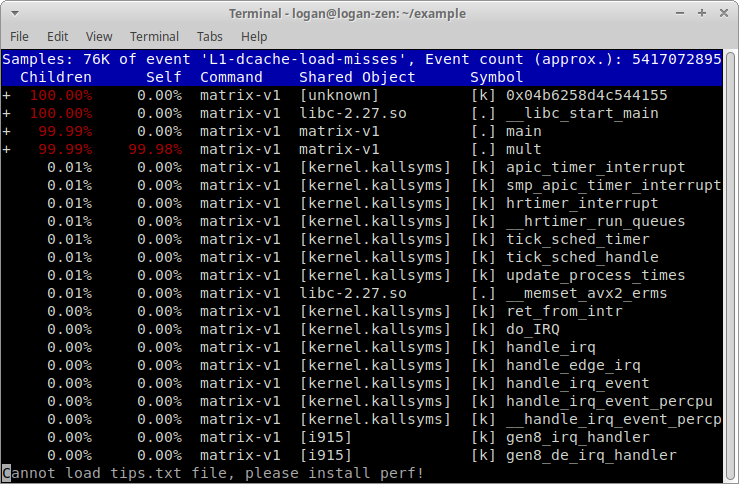
再按下 t 將左側的數字從 Percent 切換成 Period,也就是 L1 Data Cache Miss 數量的估計值:
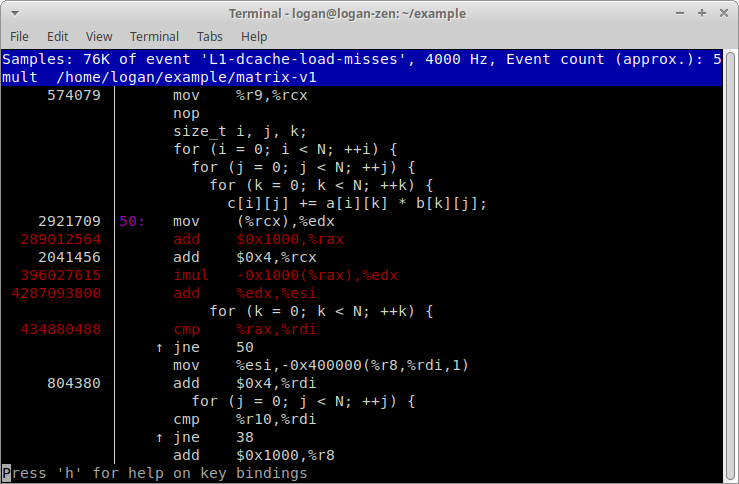
從畫面上我們可以看到可以算在 b[k][j] 上的 Cache Miss 有 imul、add 和 cmp 指令。三者加總為 5,118,001,903。如果將這個數值除以迴圈迭代次數 5 * 1024 * 1024 * 1024,可以推得 95.33% 的 b[k][j] 都會產生 L1 Data Cache Load Miss。換句話說,L1 Data Cache 完全沒有發揮效用。
| 指令 | 次數 |
|---|---|
imul -0x1000(%rax),%edx |
396,027,615 |
add %edx,%esi |
4,287,093,800 |
cmp %rax,%rdi |
434,880,488 |
| 總和 | 5,118,001,903 |
| 平均(除以 5 * 1024 * 1024 * 1024) | 95.33% |
作出上述假設後,我將程式改寫為 matrix-v2.c,讓它執行矩陣乘法之前先轉置矩陣 b:
static int32_t bT[N][N];
__attribute__((noinline))
static void transpose() {
size_t i, j;
for (i = 0; i < N; ++i) {
for (j = 0; j < N; ++j) {
bT[i][j] = b[j][i];
}
}
}
__attribute__((noinline))
static void mult() {
size_t i, j, k;
transpose();
for (i = 0; i < N; ++i) {
for (j = 0; j < N; ++j) {
for (k = 0; k < N; ++k) {
c[i][j] += a[i][k] * bT[j][k];
}
}
}
}
第九步:用同樣的指令編譯 matrix-v2.c:
$ gcc matrix-v2.c -o matrix-v2 -Wall -O2 -g -fno-omit-frame-pointer
第十步:再次使用 perf stat 測量 matrix-v2 的總體統計數據:
$ sudo perf stat \
-e cycles,instructions,L1-dcache-load-misses \
./matrix-v2
# started on Tue Jul 9 21:51:54 2019
Performance counter stats for './matrix-v2':
8,744,480,542 cycles
32,303,234,742 instructions # 3.69 insn per cycle
343,349,815 L1-dcache-load-misses
2.633926250 seconds time elapsed
2.593638000 seconds user
0.015960000 seconds sys
與之前相比,Insn Per Cycle、L1 Data Cache Miss、總花費時間都有大幅進步:
| 項目 | matrix-v1 | matrix-v2 | 差異百分比 |
|---|---|---|---|
| Insn Per Cycle(個) | 0.87 | 3.69 | +324% |
| L1 Data Cache Miss(次) | 5,118,001,903 | 343,349,815 | -93% |
| 總花費時間大幅(秒) | 22.96 | 2.63 秒 | -89% |
這大致上驗證我的假設:原本的程式幾乎沒有得到 L1 Data Cache 的好處,導致 CPU 花費不少時間等待資料。如果透過轉置矩陣讓資料的存取方式有比較好的 Spatial Locality 就能大幅改進範例程式的效能。
當然,如果要嚴謹的驗證假設,應該還要用 perf record 和 perf report 檢查 imul 的 L1 Data Cache Miss 數量。不過限於篇幅就留給讀者練習:
$ sudo perf record -g \
-e cycles,instructions,L1-dcache-load-misses \
./matrix-v2
$ sudo perf report -g graph,0.5,caller
結語
本文從取樣測量的原理談起,接著再介紹硬體效能計數器。建立基本概念後,本文後半部分介紹了 4 個常見的 perf 指令。最後以矩陣相乘示範如何測量與改進程式效能。希望這篇文章能對各位讀者的工作有所助益。如果文章有任何錯誤,也請不吝指教。
系列文章
- 使用 perf_events 分析程式效能(本文)
- 簡介 perf_events 與 Call Graph
參考資料
- Brendan Gregg, perf Examples
- Vince Weaver, The Unofficial Linux Perf Events Web-Page
- perf: Linux profiling with performance counters
- 2009, Arnaldo Carvalho de Melo, Performance Counters on Linux
- 2019, Intel Corporation, Intel 64 and IA-32 Architectures Software Developer Manuals, Volume 3, Chapter 18, Performance Monitoring, and Chapter 19 Performance Monitoring Events
- Intel Corporation, Intel Processor Event Reference
- Chandler Carruth, Tuning C++: Benchmarks, and CPUs, and Compilers! Oh My!, CppCon 2015
Note
如果你喜歡這篇文章,請追蹤羅根學習筆記粉絲專頁。最新文章都會在粉絲專頁發佈通知。




