Call Graph 是幫助 Perf Events 使用者判讀效能瓶頸成因的重要工具。Call Graph 優雅地結合「花去最多執行時間的熱區」與「為什麼要執行熱區內的程式碼」進而讓使用者能快速判斷程式有沒有改進空間。本文會從 Call Graph 的基本概念著手,再介紹記錄 Stack Trace 的注意事項與判讀 Call Graph 的方式。最後,本文會以一個文字處理程式示範如何利用 Call Graph 找出效能問題。
Call Graph 概論
perf report 印出的 Call Graph(呼叫圖)是以各個樣本的 Stack Trace(堆疊回溯)為基礎繪製而成的樹狀圖。因此本節會依序介紹 Stack Trace 與兩種不同的 Call Graph。
Stack Trace
Stack Trace(堆疊回溯)有時又稱 Call Chain(呼叫鏈)是特定時間下 Call Stack(呼叫堆疊)的記錄。舉例來說,如果在下方程式執行到函式 c 的時候記錄 Call Stack,記錄到的 Stack Trace 會是 main -> a -> b -> c:
int main() {
a();
return 0;
}
void a() {
b();
}
void b() {
c();
}
void c() {
// Dump Stack Trace
}
Stack Trace 包含「呼叫者(Caller)」與「被呼叫者(Callee)」之間的關係。在程序化程式設計(Procedural Programming)之中,呼叫者與被呼叫者之間通常有一定的因果關係,所以 Stack Trace 是尋找效能問題發生原因的重要工具。如果說最常被取樣的指令(Instruction)位址是程式執行的熱區,最常出現的 Stack Trace 就是程式進入熱區的原因。
上一篇文章提到 perf record 會以特定頻率取樣開發者想要測量的事件。我們能讓 perf record 在每次取樣時一併記錄 Stack Trace,進而蒐集大量 Stack Trace。以下方示意圖為例,橫軸為時間順序,縱軸為堆疊的變化過程,圓圈為事件的取樣點:
o o o o o o o o o o o o o o o o o
+--------------------------------------------------+
|main |
+--+-----------------------+-----------------------+
|a |a |
+--+--------+--+--------+--+--------+--+--------+
|b |c |b | |b |c |b |
+--+--+--+--+--+--+--+ +--+--+--+--+--+--+--+
|c |c | |c |c | |c |c | |c |c |
+--+--+ +--+--+ +--+--+ +--+--+
因為 Stack Trace 數量龐大,所以下一步是統計各種 Stack Trace 的樣本個數。如下表所示:
| Stack Trace | 樣本數 | 百分比 |
|---|---|---|
| main | 1 | 5.9 |
| main -> a | 2 | 11.8 |
| main -> a -> b | 4 | 23.5 |
| main -> a -> b -> c | 8 | 47.1 |
| main -> a -> c | 2 | 11.8 |
這個統計圖表有兩種不同的解讀方式:
- 由上而下的解讀是從「第一個呼叫者(First Caller)」往「最後一個被呼叫者(Last Callee)」處理 Stack Trace 並繪製 Call Graph。
- 由下而上的解讀是從「最後一個被呼叫者(Last Callee)」往「第一個呼叫者(First Caller)」處理 Stack Trace 並繪製 Call Graph。
這兩種解讀方式各有長處,本文僅以以下兩小節分述兩種方法的思路與使用方法。
Caller-based Call Graph
第一種解讀方式是由上而下(Top Down)解讀統計數據。此方法會合併有共同呼叫者的 Stack Trace。換句話說,就是將 x -> y -> z 的個數加到 x -> y 的累計數量:
| Stack Trace | 樣本數 | 百分比(Self) | 累計 | 累計百分比(Total) |
|---|---|---|---|---|
| main | 1 | 5.9 | 17 | 100.0 |
| main -> a | 2 | 11.8 | 16 | 94.1 |
| main -> a -> b | 4 | 23.5 | 12 | 70.6 |
| main -> a -> b -> c | 8 | 47.1 | 8 | 47.1 |
| main -> a -> c | 2 | 11.8 | 2 | 11.8 |
或者可以畫出以下 Caller-based Call Graph(以「呼叫者」為基礎的呼叫圖):
Total Self
+@ main 100.0 5.9
+@ a 94.1 11.8
+@ b 70.6 23.5
|+@ c 47.1 47.1
+@ c 11.8 11.8
每個 Caller-based Call Graph 的節點通常會有一組數字:
- Self 是結束於該節點的 Stack Trace 佔總體數量的百分比。
- Total 是所有有共同前綴的 Stack Trace 佔總體數量的百分比。通常程式的執行起點(例如:
main或_start)應該要很接近 100%。
Caller-based Call Graph 能讓我們知道每個函式呼叫執行的過程中會觸發多少事件。如果記錄的事件種類是 cycles,Caller-based Call Graph 就會呈現每個函式呼叫的執行時間百分比。改進程式效能的時候,我們可以從比例最高的函式開始分析與最佳化。
舉例來說,假設測量對象是一個 3D 影像渲染程式。渲染每個畫面的過程都會經過 Vertex Processing、Primitive Assembly、Rasterization、Fragment Shader 與 Per-Sample Processing。下圖為一個簡單的示意圖:
VVVVVVVVVVVVVVV PPPPP RRRRR FFFFFFFFFFFFFFFFFFFF SSSSS
如果要改進這個程式的效能可以先從 Fragment Shader 下手(40%)、再嘗試 Vertix Processing(30%)、之後再嘗試其他部分。之所以從佔比最高的部分開始是因為整體改進幅度受限於該部分原本所佔比例。舉例來說,如果減少 50% 的 Fragment Shader 執行時間,總體時間就能減少 20%。然而,同樣是減少 50% 的 Rasterization 執行時間,總體時間只能減少 5%。
Caller-based Call Graph 也可以反過來解讀。若因為某種原因其中一部分沒有辦法再進一步最佳化,我們就能知道效能改進的上限。以上面的例子,如果 Fragment Shader 和 Vertex Shader 都沒有辦法再最佳化,效能改進的上限就是減少 30% 的時間(假設剩下來計算都可以省下來)。
小結:Caller-based Call Graph 適合用來判讀能被分割為若干模組、各個模組獨立性高、且各模組都有自己的領域知識的程式。它讓我們可以從改進上限較高的模組開始分析與最佳化。
Callee-based Call Graph
第二種解讀方式是由下而上(Bottom Up)解讀統計數據。首先先反轉 Stack Trace,然後以最後一個被呼叫者分組排序,將 Stack Trace 個數較高者排在上面:
| 組別 | Stack Trace | 樣本數 | 百分比 | 組別樣本數 | 組別百分比 |
|---|---|---|---|---|---|
| c | c <- b <- a <- main | 8 | 47.1 | 10 | 58.8 |
| c <- a <- main | 2 | 11.8 | |||
| b | b <- a <- main | 4 | 23.5 | 4 | 23.5 |
| a | a <- main | 2 | 11.8 | 2 | 11.8 |
| main | main | 1 | 5.9 | 1 | 5.9 |
接著,再將每組 Stack Trace 合併為 Callee-based Call Graph(以「被呼叫者」為基礎的呼叫圖):
total self / parent = fractal
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
@ c 58.8 58.8 / 100.0 = 58.8
+@ b 47.1 47.1 / 58.8 = 80.0
|+@ a 47.1 47.1 / 47.1 = 100.0
| +@ main 47.1 47.1 / 47.1 = 100.0
+@ a 11.8 11.8 / 58.8 = 20.0
+@ main 11.8 11.8 / 11.8 = 100.0
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
@ b 23.5 23.5 / 100.0 = 23.5
+@ a 23.5 23.5 / 23.5 = 100.0
+@ main 23.5 23.5 / 23.5 = 100.0
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
@ a 11.8 11.8 / 100.0 = 11.8
+@ main 11.8 11.8 / 11.8 = 100.0
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
@main 5.9 5.9 / 100.0 = 5.9
Callee-based Call Graph 呈現的重點有二個:
- 每個函式各自觸發多少事件
- 每個函式各自被誰呼叫、每種呼叫方式佔有多少比例
以上面的例子來說,我們可以知道有 58.8% 的樣本落在函式 c。在 58.8% 之中,80.0% 是來自函式 b,20.0% 是來自函式 a。所以我們可以先思考函式 b 是否一定要呼叫函式 c,分析完 c <- b <- a <- main 之後,再分析下一種 Stack Trace。
這種分析方法讓我們能深入探究重要函式的使用情境。舉例來說,一個文字處理程式可能會多次呼叫 strcmp 與 strcpy 等字串處理函式。作為 C 語言標準函式庫的一部分,strcmp 與 strcpy 通常都已經被仔細地最佳化過,應該沒有多少改進空間。然而我們能分析這些函式的呼叫者,看看是否能從呼叫者得到額外的資訊(例如:輸入資料有一定規則或者有其它資料結構能更有效率地解決相同的問題等等),再進一步減少非必要的函式呼叫。一般而言,如果樣本大多落於基礎函式之中,Callee-based Call Graph 會是比較合適的呈現方式。
由下而上分析程式效能時,Callee-based Call Graph 會是比 Caller-based Call Graph 合理的選擇。因為 Stack Trace 之中相鄰的函式比較有因果關係,距離較遠的函式比較沒有因果關係。以下面的例子來說,strchr 和 normalizePath 的關聯比較大,和 main 的關聯比較小,因此分析為什麼要呼叫 strchr 的時候,從「最後一個被呼叫者」往「第一個呼叫者」逐步分析會比較有用:
main
-> parseFile
-> parseIncludeDirective
-> normalizePath
-> strchr
在這個例子之中,如果使用 Caller-based Call Graph,normalizePath 會散落在不同的呼叫者之下,使我們無法快速看出大部分 strchr 的呼叫者都是 normalizePath:
+---@ main
|
+---@ parseFile
|
+---@ handleError
| |
| +---@ printDiagnostic
| |
| +---@ normalizePath
| |
| +---@ strchr
|
+---@ parseIncludeDirective
| |
| +---@ normalizePath
| |
| +---@ strchr
|
+---@ parseLocationDirective
|
+---@ normalizePath
|
+---@ strchr
對照 Callee-based Call Graph 會把 normalizePath 整理在一起:
+---@ strchr
|
+---@ normalizePath
|
+---@ parseIncludeDirective
| |
| +---@ parseFile
| |
| +---@ main
|
+---@ parseLocationDirective
| |
| +---@ parseFile
| |
| +---@ main
|
+---@ printDiagnostic
|
+---@ handleError
|
+---@ parseFile
|
+---@ main
由此可知,當我們要分析為什麼一個函式會被呼叫時,Callee-based Call Graph 會是比較合理的選擇。
小結:Callee-based Call Graph 的強項是分析為什麼特定函式(熱區或效能瓶頸)會被呼叫。該函式呼叫的前後文為何。
Perf Events 與 Call Graph
本節會從概論轉向實際的 Perf Events。我會先介紹使用 perf record 命令記錄 Stack Trace 的注意事項,再介紹 perf report 命令與 Call Graph 相關的選項。
記錄 Stack Trace
如同上一篇文章所述,perf record 命令能取樣並記錄「測量對象的執行狀態」:
$ sudo perf record [-g] [--call graph [fp,dwarf,lbr]] [command]
選項 -g 會讓 perf record 在記錄各個樣本的時候,同時記錄取樣點的 Stack Trace:
$ sudo perf record -g ./callgraph
其次,使用者可以透過 --call-graph 選項指定走訪 Stack Trace 的方法:
$ sudo perf record -g --call-graph [fp,dwarf,lbr] ./callgraph
目前 perf record 支援 3 種方法:
fp(預設值)
此方法是利用 Frame Pointer 走訪每一個 Frame 並記錄呼叫堆疊上的函式。通常 CPU 會有一個暫存器記錄呼叫堆疊最後一個 Frame 的起始位址,每個 Frame 會記錄前一個 Frame 的起始位址,所以只要依序走訪每一個 Frame 就能得到 Stack Trace。
優點:這個方法能得到準確的 Stack Trace 且額外負擔亦可接受。
缺點:這個方法假設所有函式都遵循特定呼叫約定(Calling Convention)。如果有函式沒有遵循呼叫約定,
perf record就可能得到不完整的 Stack Trace。此外,部分計算機結構(包含 x86 與 x86-64)的編譯器在最佳化模式下會省略 Frame Pointer。如果要讓
perf record正確地記錄 Stack Trace,編譯待測程式時必須加上-fno-omit-frame-pointer選項。dwarf
這個方法是利用 Dwarf 除錯資訊走訪每一個 Frame。Dwarf 除錯資訊是將「正在執行的指令位址」對應到「Frame 解讀方法」的資料結構。只要有指令位址
perf record就知道如何找到當前 Frame 的起始位址與前一個 Frame 的起始位置。優點:這個方法產生的 Stack Trace 最詳儘。Inline 函式也能被正確地列在 Stack Trace 裡面(以
(inlined)標記)。缺點:這個方法在記錄 Stack Trace 時,需要花時間解讀除錯資訊,因此這個方法的額外負擔最高、需要最久的記錄時間。此外,這個方法產生的記錄檔案也是最大的。
其次,這個方法需要額外的除錯資訊,編譯待測程式時必須加上
-g選項。這個方法不適合用於測量大型程式,因為除錯資訊的大小通常比程式本身大若干倍。考量觀察者效應,過大的除錯資訊可能增加測量結果的不準確度。lbr
LBR 是 Last Branch Record(最後分支記錄)的縮寫。這個方法是讓處理器記錄 Branch Instruction(分支指令)跳躍的「來源位址」與「目標位址」。每當處理器執行一個
call指令之後,就將該call指令的來源位址與目標位址記錄於 LBR 暫存器。同樣地,每當處理器執行一個ret指令之後,就會從 LBR 暫存器移除最後一組記錄。最後perf record會將 LBR 暫存器每一組記錄的來源位址與最後一組的目標位址整理成 Stack Trace。優點:這個方法的額外負擔很低,而且不需調整編譯器選項。
缺點:因為硬體能保留的分支記錄結果是有限的,所以當堆疊深度過深時,會得到不完整的 Stack Trace。這可能會引入一些不確定性。其次,就我目前所知,只有 Haswell 微架構之後的 Intel 處理器才支援以 Last Branch Record 記錄 Call Stack。
編譯器選項也會影響 Stack Trace 記錄。以下列出 3 個會影響 Stack Trace 的編譯器選項:
-fno-omit-frame-pointer會阻止編譯器省略「設定 Frame Pointer」的指令。如前所述,如果要以fp模式記錄 Stack Trace,就必須在編譯待測程式時加上此選項。-fno-optimize-sibling-calls會阻止編譯器施行 Sibling Call Optimization。當一個函式的最後一個述句是回傳另一個函式的回傳值時,我們稱該述句為 Tail Call(如下方
example1)。若該函式的的參數型別(Argument Type)與回傳型別(Return Type)與被呼叫者一致,則將該類 Tail Call 細分為 Sibling Call(如下方example2)。因為 Sibling Call 已經是這個函式的最後步驟,所以這個函式的 Frame 其實是可以被重複利用的。Sibling Call Optimization 就是讓被呼叫者直接覆蓋呼叫者的 Frame。這個最佳化會讓
perf record記錄到不存在於程式碼的 Stack Trace。以下方的main函式為例,理論上應該不會有main -> dest2,然而因為 Sibling Call Optimization,中間的example2函式會被覆蓋,從而產生不應存在的 Stack Trace。當 Sibling Call 讓 Call Graph 看起來不太正確時,可以在編譯待測程式時加上
-fno-optimize-sibling-calls。int example1(int a) { // ... return dest1(a, a + 1); // Tail Call } int example2(int a) { // ... return dest2(a + 1); // Sibling Call } int main() { int x = example2(5); // ... }
-fno-inline會阻止編譯器將「函式呼叫」代換「為被呼叫者的程式碼」。在最佳化模式下,編譯器會嘗試將函式呼叫改寫為 Inline Function(內嵌函式)的程式碼。然而,如果使用
fp或lbr記錄 Stack Trace,這些 Inline Function 就無法被記錄於 Stack Trace 上。雖然測量效能時不建議關閉 Function Inlining(函式內嵌),但是如果你需要詳細的 Stack Trace,你可以加上
-fno-inline。如果不想要全面關閉 Function Inlining,也可以將想要測試的函式標上__attribute__((noinline))屬性,編譯器就不會內嵌該函式。
實際操作
現在讓我們以範例程式展示各種選項的差異。本節使用的範例程式為 callgraph.c,部分程式碼節錄如下:
__attribute__((noinline))
void D() {
COMPUTE(1, 'D');
}
__attribute__((noinline))
void C() {
D();
COMPUTE(NUM_ROUNDS, 'C');
}
__attribute__((noinline))
void B() {
COMPUTE(NUM_ROUNDS, 'B');
C();
C();
}
__attribute__((noinline))
void A() {
COMPUTE(NUM_ROUNDS, 'A');
B();
C();
B();
}
int main() {
COMPUTE(NUM_ROUNDS, 'M');
A();
A();
return 0;
}
請先下載 callgraph.c 並使用以下命令編譯程式碼:
$ gcc -g -O2 -fno-omit-frame-pointer \
callgraph.c -o callgraph
接著分別使用以下 perf record 命令測量 callgraph 的效能:
$ sudo perf record -g --call-graph fp \
-o callgraph.fp.perf.data ./callgraph
$ sudo perf record -g --call-graph dwarf \
-o callgraph.dwarf.perf.data ./callgraph
$ sudo perf record -g --call-graph lbr \
-o callgraph.lbr.perf.data ./callgraph
第一個明顯的差異是記綠檔案的大小:
$ ls -lh callgraph.*.perf.data
-rw------- 1 root root 198M Aug 13 21:43 callgraph.dwarf.perf.data
-rw------- 1 root root 2.2M Aug 13 21:43 callgraph.fp.perf.data
-rw------- 1 root root 4.5M Aug 13 21:44 callgraph.lbr.perf.data
上面的結果顯示「dwarf 產生的記錄檔案」會比「fp 或 lbr 產生的記檔案」大兩個數量級。「lbr 產生的記錄檔案」會稍微比「fp 產生的記錄檔案」大。順帶一提,記錄檔案並不是越大越好,有時候小的記錄檔案也能提供精準且詳細的資訊。所以以實務經驗來說,正常規模的程式不太可能使用 dwarf 記錄 Stack Trace。
接著,我們可以用以下指令觀察記錄檔案的內容(下節會再進一步介紹):
$ sudo perf report --stdio -i [filename]
為了方便比較,以下輸出都只節選以 _start 函式(一個執行檔第一個被執行的函式)開始的 Call Graph。
首先是 dwarf 產生的記錄檔案:
$ sudo perf report --stdio -i callgraph.dwarf.perf.data
99.99% 0.00% callgraph callgraph [.] _start
|
---_start
__libc_start_main
main
|
|--58.80%--A
| |
| |--23.54%--C
| |
| --23.53%--B
| |
| --11.79%--C
|
|--23.52%--B
| |
| --11.77%--C
|
--11.77%--C
其次是 fp 產生的記錄檔案(雖然輸出結果沒有 _start 但可以透過 __libc_start_main 推得 0x64e258d4c544155 是 _start 的位址):
$ sudo perf report --stdio -i callgraph.fp.perf.data
99.99% 0.00% callgraph [unknown] [.] 0x064e258d4c544155
|
---0x64e258d4c544155
__libc_start_main
main
|
|--58.81%--A
| |
| |--23.57%--C
| |
| --23.52%--B
| |
| --11.78%--C
|
|--23.51%--B
| |
| --11.78%--C
|
--11.79%--C
最後是 lbr 產生的記錄檔案:
$ sudo perf report --stdio -i callgraph.lbr.perf.data
99.99% 0.00% callgraph callgraph [.] _start
|
---_start
__libc_start_main
main
|
|--82.26%--A
| |
| |--35.23%--B
| | |
| | --11.77%--C
| |
| --11.82%--C
|
--11.79%--B
C
觀察以上結果,我們能注意到 fp 和 dwarf 兩種方法產生的結果相似,而 lbr 產生的結果與其他兩者不同。然而,三種方法的結果都和程式碼有所出入。這些差異都是 Sibling Call Optimization 造成的:
對於
fp和dwarf而言,Sibling Call Optimization 會重覆利用同一個 Frame,因此部分函式的呼叫者變成A函式。對於
lbr而言,Sibling Call Optimization 會將 Sibling Call 原本會使用的call與ret指令代換為jmp指令。因此有些 Stack Trace 會令人感到困惑。舉例來說,
_start -> __libc_start_main -> main -> B -> C對應到「A函式第二次呼叫B函式」且「B函式第一次呼叫C函式」。此時,LBR 暫存器上的記錄依序為:來源位址 目標位址 _start __libc_start_main __libc_start_main main main A B C 若只截取每組記錄的來源位址與最後一組的目標位址,Stack Trace 就會變成
main -> B -> C。
為了看到比較合理的 Stack Trace,請加上 -fno-optimize-sibing-calls 並重新編譯 callgraph.c:
$ gcc -g -O2 -fno-omit-frame-pointer -fno-optimize-sibling-calls \
callgraph.c -o callgraph
重新再測量一次:
$ sudo perf record -g --call-graph fp \
-o callgraph.fp.perf.data ./callgraph
這次的結果大致上與程式碼相符:
$ sudo perf report --stdio -i callgraph.fp.perf.data
99.99% 0.00% callgraph [unknown] [k] 0x063e258d4c544155
|
---0x63e258d4c544155
__libc_start_main
main
|
--94.10%--A
|
|--70.60%--B
| |
| --47.12%--C
|
--11.77%--C
以此例而言,在關閉 Sibling Call Optimization 之後,三種記錄 Stack Trace 的方法都會得到類似的結果。上面只以 fp 為例,dwarf 與 lbr 就留給讀者練習。
呈現 Call Graph
使用 perf report 呈現 Call Graph 的指令如下:
$ sudo perf report \
[--tui|--stdio] \
[--children|--no-children] \
[-g [fractal|graph],0.5,[caller|callee]] \
-i perf.data
--tui 與 --stdio 是兩種不同的輸出模式:
--tui會提供一個互動式純文字介面讓使用者選擇要展開的節點。--stdio會直接將所有結果一次印出。
一般常用的模式 --tui,這也是 perf report 的預設值:
$ sudo perf report --tui -i perf.data
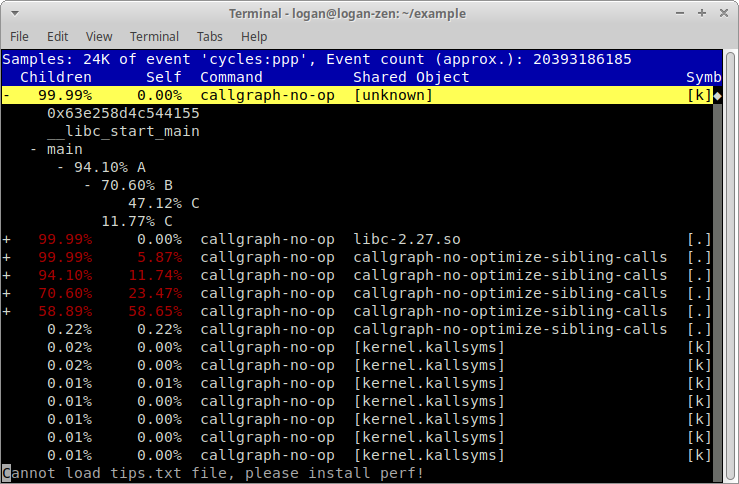
有時候 --stdio 會有比較完整的資訊,下圖是 --stdio 的執行畫面:
$ sudo perf report --stdio -i [perf.data]
99.99% 0.00% callgraph [unknown] [k] 0x063e258d4c544155
|
---0x63e258d4c544155
__libc_start_main
main
|
--94.10%--A
|
|--70.60%--B
| |
| --47.12%--C
|
--11.77%--C
因為截取 --stdio 的輸出結果比較容易,所以本文大部分的例子都是使用 perf report --stdio 產生的。
其次,如果指定 --children 選項,perf report 會將「被呼叫者」的樣本數量加進「呼叫者」的統計數字。反之,如果指定 --no-children 選項,perf record 就不會累加統計數字。在 2013 年之後,perf report 的預設值是 --children。
接著 -g 選項是用以指定 Call Graph 的繪製參數。通常我們會指定三個參數(以逗號分開):
- 第一個參數是各個節點百分比的計算方法。如果指定
graph則會直接顯示該節點佔總體樣本數的比例。如果指定fractal會顯示一個節點和其他平級節點相比所佔的比例。 - 第二個參數是繪製 Call Graph 的門檻值。如果一個 Stack Trace 的數量與總體樣本數相比低於門檻值,則忽略該 Stack Trace。此數值以百分比表示。如果指定的數值為 0.5,則佔比低於 0.5% 的 Stack Trace 會被忽略。
- 第三個參數是 Stack Trace 的走訪順序。如果指定
caller就會顯示 Caller-based Call Graph。反之,如果指定callee則會顯示 Callee-based Call Graph。
-g 選項的預設值會受 --[no-]children 選項影響:
| 選項 | -g 預設值 |
|---|---|
--children |
graph,0.5,caller |
--no-children |
graph,0.5,callee |
實際操作
請先以上一小節的方法編譯並執行 callgraph.c:
$ gcc -g -O2 -fno-omit-frame-pointer -fno-optimize-sibling-calls \
callgraph.c -o callgraph
$ sudo perf record -g --call-graph fp \
-o callgraph.fp.perf.data ./callgraph
第一個實驗先以 --children 搭配 -g graph,0.5,caller 觀察 Call Graph:
$ sudo perf report -i callgraph.fp.perf.data --stdio \
--children -g graph,0.5,caller
99.99% 0.00% callgraph [unknown] [k] 0x063e258d4c544155
|
---0x63e258d4c544155
__libc_start_main
main
|
--94.10%--A
|
|--70.60%--B
| |
| --47.12%--C
|
--11.77%--C
這個 Call Graph 沒有函式 D,因為 main -> A -> B -> C -> D 的比例低於 0.5%。如果將 -g 選項的門檻值下調至 0.1,就看得到函式 D:
$ sudo perf report -i callgraph.fp.perf.data --stdio \
--children -g graph,0.1,caller
99.99% 0.00% callgraph [unknown] [k] 0x063e258d4c544155
|
---0x63e258d4c544155
__libc_start_main
main
|
--94.10%--A
|
|--70.60%--B
| |
| --47.12%--C
| |
| --0.18%--D
|
--11.77%--C
如果進一步將門檻值下調至 0.0,則會看到 Linux 核心處理中斷的函式:
$ sudo perf report -i callgraph.fp.perf.data --stdio \
--children -g graph,0.0,caller
99.99% 0.00% callgraph [unknown] [k] 0x063e258d4c544155
|
---0x63e258d4c544155
__libc_start_main
main
|
|--94.10%--A
| |
| |--70.60%--B
| | |
| | |--47.12%--C
| | | |
| | | |--0.18%--D
| | | |
| | | |--0.01%--apic_timer_interrupt
| | | | smp_apic_timer_interrupt
| | | | |
| | | | |--0.01%--hrtimer_interrupt
| | | | | __hrtimer_run_queuess
| | | | | tick_sched_timer
| | | | | tick_sched_handle
| | | | | update_process_times
| | | | | scheduler_tick
| | | | | perf_event_task_tick
| | | | | |
| | | | | --0.00%--x86_pmu_enable
| | | | | intel_tfa_pmu_enable_all
| | | | | __intel_pmu_enable_all.constprop.25
| | | | | native_write_msr
因為這些函式比例很低,反而會在視覺上干擾 Call Graph 判讀工作,所以我們通常還是會指定一個門檻值。
先前的例子我們都只截取以 _start 為起點的 Call Graph。現在我們把目光轉向函式 B 與函式 C 的 Call Graph:
$ sudo perf report -i callgraph.fp.perf.data --stdio \
--children -g graph,0.5,caller
... 中略 ...
70.60% 23.47% callgraph callgraph [.] B
|
|--47.13%--B
| |
| --47.12%--C
|
--23.47%--0x63e258d4c544155
__libc_start_main
main
A
B
58.89% 58.65% callgraph callgraph [.] C
|
--58.65%--0x63e258d4c544155
__libc_start_main
main
A
|
|--46.92%--B
| C
|
--11.72%--C
在 Caller-based Call Graph 模式下,perf report 會以「Stack Trace 是否以該函式結束」分為兩類:
- 第一類是結尾不是該函式的 Stack Trace。
perf report會從該函式第一次出現的位置合併此類 Stack Trace。這呈現的是該函式裡面的函式呼叫各佔去多少比例。- 函式
B的 Call Graph 顯示函式B裡面的函式呼叫大多都是呼叫函式C。 - 函式
C的 Call Graph 顯示函式C只出現於 Stack Trace 的結尾。(嚴格的說,其實函式C有呼叫函式D,但是因為低於門檻值而被省略。)
- 函式
- 第二類是結尾是該函式的 Stack Trace。
perf report會以_start函式為起點,繪製其他函式是如何呼叫該函式。- 函式
B的 Call Graph 顯示所有結束於函式B的 Stack Trace 都是以_start -> __libc_start_main -> A -> B開頭。 - 函式
C的 Call Graph 將函式C的 Stack Trace 分為兩類:46.92% 的 Stack Trace 有經過函式B,11.72% 的 Stack Trace 是直接從函式A跳至函式C。
- 函式
我自己在判讀 Caller-based Call Graph 的時候會著重第一類 Stack Trace。因為我想知道的是一個函式是如何被分拆為若干個函式呼叫。其次,我想要知道各個函式呼叫佔去多少比例,以方便我決定要分析哪一部分。
除了比例總和(Self)之外,我幾乎不看第二類 Stack Trace 產生的 Call Graph,因為 Caller-based Call Graph 會傾向把該函式被呼叫的原因打散到不同的子樹。如果想要知道一個函式為什麼被呼叫,Callee-based Call Graph 會是比較好的選擇。
第二個實驗請改用 --no-children 搭配 -g graph,0.5,callee 觀察 Call Graph:
$ sudo perf report -i callgraph.fp.perf.data --stdio \
--no-children -g graph,0.5,callee
58.65% callgraph-no-op callgraph-no-optimize-sibling-calls [.] C
|
---C
|
|--46.92%--B
| A
| main
| __libc_start_main
| 0x63e258d4c544155
|
--11.72%--A
main
__libc_start_main
0x63e258d4c544155
23.47% callgraph-no-op callgraph-no-optimize-sibling-calls [.] B
|
--23.46%--B
A
main
__libc_start_main
0x63e258d4c544155
在 perf report 會先以各個函式的樣本數量排序各個函式的 Callee-based Call Graph。取樣點比較多的函式就會被排在前面。接著以 Stack Trace 的最後一個「被呼叫者」為起點,繪製每一個 Call Graph。以上圖為例,以函式 C 結束的 Stack Trace 佔總樣本數的 58.65%。由函式 B 呼叫函式 C 的 Stack Trace 佔總樣本數的 46.92%。直接由函式 A 呼叫函式 C 的 Stack Trace 佔總樣本數的 11.72%。
看到這個 Callee-based Call Graph 之後,我們能思考:函式 B 一定要呼叫函式 C 嗎?有沒有更有效率的方法能實作函式 B 的功能?
在判讀 Callee-based Call Graph 的時候,我們有時候會想要知道平級節點的相對關係。只要指定 -g fractal,0.5,callee 選項,perf report 就能幫我們換算比例:
$ sudo perf report -i callgraph.fp.perf.data --stdio \
--no-children -g fractal,0.5,callee
58.65% callgraph callgraph [.] C
|
---C
|
|--80.01%--B
| A
| main
| __libc_start_main
| 0x63e258d4c544155
|
--19.99%--A
main
__libc_start_main
0x63e258d4c544155
... 下略 ...
這個 Call Graph 顯示:在以函式 C 結束的 Stack Trace 之中,80.01% 是由函式 B 呼叫,19.99% 是由函式 A 呼叫。有時候平級節點之間的比例會比總體比例好用,我在分析效能的時候有時會交互使用。
備註:上面的範例 --children 都是搭配 -g *,*,caller 而 --no-children 都是搭配 -g *,*,callee。雖然 perf report 能讓我們任意指定,但是我的實驗結果讓我覺得其他組合並不實用。然而作為練習,我建議大家一併嘗試不同的排列組合。
Flame Graph
Flame Graph(火焰圖)是 Caller-based Call Graph 的變型。它是由 Brendan Gregg 開發並發揚光大。Flame Graph 的橫軸是事件數量百分比,縱軸是呼叫堆疊。每個函式呼叫都會依照 Stack Trace 數量百分比繪製橫向長條。最下面是各個 Stack Trace 第一個呼叫者,最上面是各個 Stack Trace 最後一個被呼叫者。有同樣前綴的 Stack Trace 都會被整理在一起。因為 Flame Graph 直接產生 SVG 向量圖,所以使用者可以迅速看出佔比最高的 Stack Trace。若函式名稱比較長,使用者也可以將滑鼠游標指向各個長條圖,其代表的函式名稱會顯示在右下方:

實際操作
首先,請先下載 FlameGraph 的程式碼:
$ git clone https://github.com/brendangregg/FlameGraph
接著,將 FlameGraph 目錄加到 PATH 環境變數:
$ export PATH=$(pwd)/FlameGraph:$PATH
最後,以 perf script 讀取 perf_events 記錄檔案,再交由 stackcollapse-perf.pl 與 flamegraph.pl 後製:
$ sudo perf script -i perf.data | \
stackcollapse-perf.pl --all | \
flamegraph.pl --color=java --hash > flamegraph.svg
產生的 flamegraph.svg 就是與記錄檔案對應的 Flame Graph(如上圖)。
綜合練習:文字處理程式
現在我們以一個文字處理程式(textprocessor1.c)示範如何最佳化一個實際的程式。這個程式會將每一行以空白分割為「鍵(Key)」與「值(Value)」,以每行的「鍵」分組,將每行的「值」加進對應的組別。輸出時,以字典順序排序「鍵」與「值」,並分組印出。
以下是一個簡單的範例輸入:
BB y
AA x
AA xx
AA x
BB x
對應的輸出結果為:
AA
x
x
xx
BB
x
y
受限與篇幅,本文僅簡述 textprocessor1.c 的架構:
string_list是儲存「值」的串列。string_list_new會配置與建構一個string_list物件。string_list_delete會解構與釋放一個string_list物件。string_list_append會在string_list尾端加上一個值。string_list_reserve是用以確保string_list有充足空位的函式。
string_map是儲存鍵值對應的資料結構。string_map_new會配置與建構一個string_map物件。string_map_delete會解構與釋放一個string_map物件。string_map_add會將一組鍵值加進string_map物件。如果string_map已經有該鍵,則會直接將值加進對應的string_list物件。如果string_map還沒有該鍵,則會在string_map新增一筆記錄指向一個新的string_list物件,並將值加進該string_list。
現在開始進行分析:
第一步,請先下載並編譯 textprocessor1.c:
$ gcc -O2 -fno-omit-frame-pointer -fno-inline -g \
textprocessor1.c -o textprocessor1
第二步,請下載 gen_test_data.py 以產生測資:
$ python gen_test_data.py > input.txt
第三步,以 perf stat 測量時間:
$ sudo perf stat \
./textprocessor1 input.txt /dev/null
# started on Sun Oct 6 21:40:42 2019
Performance counter stats for './textprocessor1 input.txt /dev/null':
1,676.09 msec task-clock # 1.000 CPUs utilized
4 context-switches # 0.002 K/sec
0 cpu-migrations # 0.000 K/sec
106,012 page-faults # 0.063 M/sec
5,016,328,300 cycles # 2.993 GHz
10,217,335,197 instructions # 2.04 insn per cycle
2,253,680,016 branches # 1344.605 M/sec
15,744,959 branch-misses # 0.70% of all branches
1.676458791 seconds time elapsed
1.420940000 seconds user
0.255449000 seconds sys
第四步,以 perf record -g 取樣:
$ sudo perf record -g --call-graph fp \
-o textprocessor1.fp.perf.data \
./textprocessor1 input.txt /dev/null
第五步,以 perf report --children 觀察 Caller-based Call Graph:
$ sudo perf report --stdio --children \
-i textprocessor1.fp.perf.data
47.91% 0.00% textprocessor1 [unknown] [.] 0x08ce258d4c544155
|
---0x8ce258d4c544155
__libc_start_main
|
--47.67%--main
|
|--29.52%--__strcmp_sse2_unaligned
|
|--14.55%--string_map_add
|
|--1.59%--string_map_delete
| |
| --1.53%--cfree@GLIBC_2.2.5
|
--1.01%--string_list_append
我們遇到一個非預期的問題。理論上,在 Caller-based Call Graph 裡,以 _start 函式為起點的 Stack Trace 數量應該要很接近 99%,然而上面的結果顯示只有 47.91% 的 Stack Trace 是以 _start 函式為起點。
如果再往下看,會看到一些不合理的 Call Graph。舉例來說,下面 __strcmp_sse2_unaligned 函式有 9.41% 的樣本看不到其「呼叫者」或「被呼叫者」:
39.01% 34.26% textprocessor1 libc-2.27.so [.] __strcmp_sse2_unaligned
|
|--29.57%--0x8ce258d4c544155
| __libc_start_main
| main
| |
| |--24.95%--__strcmp_sse2_unaligned
| |
| --4.62%--string_map_add
|
--9.41%--__strcmp_sse2_unaligned
深入研究後,我發現問題的成因是 C 語言函式庫 glibc 在編譯的時候沒有加上 -fno-omit-frame-pointer。然而要安裝不同的 glibc 很麻煩,所以我直接改用 lbr 記錄 Stack Trace(如果你的 CPU 不支援,也可以改用 dwarf)。
第六步,重新以 perf record -g --call-graph lbr 取樣:
$ sudo perf record -g --call-graph lbr \
-o textprocessor1.lbr.perf.data \
./textprocessor1 input.txt /dev/null
第七步,再次以 perf report --children 觀察 Caller-based Call Graph:
$ sudo perf report --stdio --children \
-i textprocessor1.lbr.perf.data
99.36% 0.00% textprocessor1 textprocessor1 [.] _start
|
---_start
__libc_start_main
main
|
|--45.63%--string_map_add
| |
| --28.90%--strcmp@plt
|
|--13.05%--string_list_append
| |
| |--11.81%--__strdup
| | |
| | |--9.97%--malloc
| | | _int_malloc
| | | |
| | | |--3.87%--0xffffffff8c2010ee
這次以 _start 函式為起點的 Stack Trace 佔總樣本數量的 99.36%。這符合我們的預期。其次,我們可以看到 string_map_add 函式呼叫的 strcmp 函式佔去 28.90%,值得進一步分析。(備註:這個 Call Graph 有很多 0xffffffff8c2010ee 之類的函式。這些其實是 Linux 核心內部的函式,可以暫時忽略。)
第八步,反過來用 perf report --no-children 觀察 Callee-based Call Graph:
$ sudo perf report --stdio --no-children \
-i textprocessor1.lbr.perf.data
33.44% textprocessor1 libc-2.27.so [.] __strcmp_sse2_unaligned
|
|--23.73%--strcmp@plt
| string_map_add
| main
| __libc_start_main
| _start
|
|--4.95%--string_map_add
| main
| __libc_start_main
| _start
|
--4.68%--str_ptr_compare
msort_with_tmp.part.0
|
|--4.13%--msort_with_tmp.part.0
我們能看到 string_map_add 函式裡的 strcmp 函式呼叫確實是很大的問題。我們看看 textprocessor1.c 的程式碼:
int string_map_add(string_map *self, const char *key,
const char *value) {
assert(self != NULL);
assert(key != NULL);
assert(value != NULL);
// Find the matching key and add the value to the list.
size_t i;
for (i = 0; i < self->num_elements; ++i) {
if (strcmp(key, self->elements[i].key) == 0) {
return string_list_append(self->elements[i].value, value);
}
}
// ... skipped ...
string_map_entry *ent = &self->elements[self->num_elements];
ent->key = new_key;
ent->value = new_list;
self->num_elements++;
return 1;
}
這段程式透過「循序搜尋」尋找對應的「鍵」。然而從演算法的時間複雜度來看,這是沒有效率的選擇。在不改變架構的前提下,我把 string_map 改以 Sorted Array 與 Binary Search 實作(textprocessor2.c):
int string_map_add(string_map *self, const char *key,
const char *value) {
assert(self != NULL);
assert(key != NULL);
assert(value != NULL);
// Find the matching key and add the value to the list.
size_t start = 0;
size_t end = self->num_elements;
while (start < end) {
size_t mid = start + (end - start) / 2;
int cmp = strcmp(self->elements[mid].key, key);
if (cmp == 0) {
return string_list_append(self->elements[mid].value, value);
} else if (cmp < 0) {
start = mid + 1;
} else {
end = mid;
}
}
// ... skipped ...
memmove(self->elements + start + 1, self->elements + start,
sizeof(string_map_entry) * (self->num_elements - start));
string_map_entry *ent = &self->elements[start];
ent->key = new_key;
ent->value = new_list;
self->num_elements++;
return 1;
}
第九步,下載 textprocessor2.c 並重新編譯:
$ gcc -O2 -fno-omit-frame-pointer -fno-inline -g \
textprocessor2.c -o textprocessor2
重新以 perf stat 測量:
$ sudo perf stat \
./textprocessor2 input.txt /dev/null
# started on Sun Oct 6 21:40:44 2019
Performance counter stats for './textprocessor2 input.txt /dev/null':
1,090.55 msec task-clock # 1.000 CPUs utilized
5 context-switches # 0.005 K/sec
0 cpu-migrations # 0.000 K/sec
106,011 page-faults # 0.097 M/sec
2,973,836,135 cycles # 2.727 GHz
2,754,413,677 instructions # 0.93 insn per cycle
555,628,887 branches # 509.493 M/sec
13,331,051 branch-misses # 2.40% of all branches
1.090851312 seconds time elapsed
0.910295000 seconds user
0.180455000 seconds sys
很明顯地,使用的時間從 1.676 秒降到 1.091 秒(-34.93%),是一個好的開始。
重新以 perf report -g --call-graph lbr 取樣:
$ sudo perf record -g --call-graph lbr \
-o textprocessor2.lbr.perf.data \
./textprocessor2 input.txt /dev/null
第十步,再次使用 perf report --no-children 觀察 Callee-based Call Graph:
$ sudo perf report --stdio --no-children \
-i textprocessor2.lbr.perf.data
14.35% textprocessor2 libc-2.27.so [.] cfree@GLIBC_2.2.5
|
--14.31%--free@plt
string_list_delete
string_map_delete
main
__libc_start_main
_start
這次花去最多時間的函式是 glibc 的 free 函式。free 函式的主要工作是更新記憶體配置器的資料結構,使得之後的 malloc 函式呼叫能重複利用這些被釋放的記憶體。然而,對我們的範例程式而言,所有的 free 函式都是在程式最後的清理階段呼叫的,其實我們並不在乎這些記憶體能不能被重複使用。一個不負責任的作法是直接刪除所有的 free 函式呼叫。比較正規的作法是引入 Arena Allocator。Arena Allocator 會向 C 語言函式庫的記憶體配置器要求一大塊記憶體,然後自行管理記憶體。使用完畢之後,再一次歸還所有記憶體。textprocessor3.c 實作了一個簡單的 Arena Allocator,並將原本的 malloc 函式呼叫代換為 arena_alloc 函式呼叫:
struct arena_allocator {
char *buf_head;
size_t begin;
};
arena_allocator *arena_new() {
arena_allocator *self =
(arena_allocator *)malloc(sizeof(arena_allocator));
if (!self) {
return NULL;
}
self->buf_head = NULL;
self->begin = 0;
return self;
}
void arena_delete(arena_allocator *self) {
if (self) {
void *cur = self->buf_head;
while (cur != NULL) {
void *next = *(void **)cur;
free(cur);
cur = next;
}
free(self);
}
}
void *arena_alloc(arena_allocator *self, size_t size) {
assert(self != NULL);
size_t aligned_begin = ARENA_ALLOC_ALIGN(self->begin);
size_t aligned_end = aligned_begin + size;
if (self->buf_head && aligned_end <= ARENA_ALLOC_BUF_SIZE) {
void *p = self->buf_head + aligned_begin;
self->begin = aligned_end;
return p;
}
size_t alloc_size = MAX(sizeof(void *) + size, ARENA_ALLOC_BUF_SIZE);
char *buf = (char *)malloc(alloc_size);
if (!buf) {
return NULL;
}
*(void **)buf = self->buf_head;
self->buf_head = buf;
self->begin = sizeof(void *) + size;
return buf + sizeof(void *);
}
第十一步,下載 textprocessor3.c 並重新編譯:
$ gcc -O2 -fno-omit-frame-pointer -fno-inline -g \
textprocessor3.c -o textprocessor3
重新以 perf stat 測量:
$ sudo perf stat \
./textprocessor3 input.txt /dev/null
# started on Sun Oct 6 21:40:45 2019
Performance counter stats for './textprocessor3 input.txt /dev/null':
841.33 msec task-clock # 1.000 CPUs utilized
8 context-switches # 0.010 K/sec
0 cpu-migrations # 0.000 K/sec
105,264 page-faults # 0.125 M/sec
2,595,040,498 cycles # 3.084 GHz
2,600,730,011 instructions # 1.00 insn per cycle
545,582,983 branches # 648.473 M/sec
13,110,046 branch-misses # 2.40% of all branches
0.841712243 seconds time elapsed
0.641217000 seconds user
0.200380000 seconds sys
使用的時間再次從 1.091 秒降到 0.842 秒(-22.84%)。
第十二步,再次使用 perf record -g --call-graph lbr 取樣:
$ sudo perf record -g --call-graph lbr \
-o textprocessor3.lbr.perf.data \
./textprocessor3 input.txt /dev/null
然後使用 perf report --no-children 觀察 Callee-based Call Graph:
$ sudo perf report --stdio --no-children \
-i textprocessor3.lbr.perf.data
16.11% textprocessor3 libc-2.27.so [.] __strcmp_sse2_unaligned
|
|--10.41%--str_ptr_compare
| msort_with_tmp.part.0
| |
... skipped ...
| |
| --1.13%--__GI___qsort_r
| string_map_sort
| main
| __libc_start_main
| _start
|
--5.49%--strcmp@plt
string_map_add
main
__libc_start_main
_start
12.77% textprocessor3 libc-2.27.so [.] __strlen_avx2
|
|--11.93%--@plt
| _IO_fputs
| string_map_dump
| main
| __libc_start_main
| _start
|
--0.82%--strlen@plt
string_list_append
main
__libc_start_main
_start
這次次數最高的函式是 __strcmp_sse2_unaligned。然而呼叫它的呼叫者分別是 string_map_sort 與 string_map_add,在不改動資料結構的前提下,能最佳化的空間應該不大了。
接著,我們可以把目光轉向次高的函式 __strlen_avx2。它的呼叫者是 fputs。因為 fputs 的參數只有一個 C-style String,所以它必須呼叫 strlen 函式取得字串長度。
textprocessor3.c 在 string_list_append 的時候就會計算字串長度,所以或許我們可以記錄字串長度,再直接呼叫 fwrite 節省 strlen。在這個構想下,textprocessor4.c 定義了 string:
struct string {
size_t len;
char str[];
};
int string_list_append(string_list *self, const char *str,
arena_allocator *allocator) {
size_t len = strlen(str);
string *new_str = (string *)arena_alloc(
allocator, sizeof(string) + len + 1);
if (!new_str) {
return 0;
}
new_str->len = len;
memcpy(new_str->str, str, len + 1);
// ... skipped ...
}
void string_map_dump(string_map *self, FILE *fp) {
size_t i, j;
for (i = 0; i < self->num_elements; ++i) {
// ... skipped ...
for (j = 0; j < list->num_elements; ++j) {
fputc('\t', fp);
fwrite(list->elements[j]->str, list->elements[i]->len, 1, fp);
fputc('\n', fp);
}
}
}
第十三步,下載 textprocessor4.c 並重新編譯:
$ gcc -O2 -fno-omit-frame-pointer -fno-inline -g \
textprocessor4.c -o textprocessor4
重新以 perf stat 測量:
$ sudo perf stat \
./textprocessor4 input.txt /dev/null
# started on Sun Oct 6 21:40:46 2019
Performance counter stats for './textprocessor4 input.txt /dev/null':
824.87 msec task-clock # 1.000 CPUs utilized
3 context-switches # 0.004 K/sec
0 cpu-migrations # 0.000 K/sec
106,827 page-faults # 0.130 M/sec
2,546,158,876 cycles # 3.087 GHz
2,529,577,956 instructions # 0.99 insn per cycle
520,276,190 branches # 630.740 M/sec
12,139,306 branch-misses # 2.33% of all branches
0.825163632 seconds time elapsed
0.601894000 seconds user
0.223219000 seconds sys
使用的時間好像是從 0.842 秒降到 0.8252 秒。然而這其實是測量誤差。多跑幾次偶爾會有 textprocessor4.c 跑的比較慢的數據(儘管差異不大)。我們可以用 perf record 取樣,分析為何前面的最佳化沒有發揮作用:
$ sudo perf record -g --call-graph lbr \
-o textprocessor4.lbr.perf.data \
./textprocessor4 input.txt /dev/null
$ sudo perf report --stdio --no-children \
-i textprocessor4.lbr.perf.data
19.11% textprocessor4 libc-2.27.so [.] __memmove_avx_unaligned_erms
|
|--12.86%--@plt
| |
| |--11.31%--_IO_file_xsputn@@GLIBC_2.2.5
| | _IO_fwrite
| | string_map_dump
| | main
| | __libc_start_main
| | _start
... skipped ...
對照 textprocessor3.c 的 Call Graph:
$ sudo perf report --stdio --no-children \
-i textprocessor3.lbr.perf.data
12.77% textprocessor3 libc-2.27.so [.] __strlen_avx2
|
|--11.93%--@plt
| _IO_fputs
| string_map_dump
| main
| __libc_start_main
| _start
... skipped ...
8.31% textprocessor3 libc-2.27.so [.] __memmove_avx_unaligned_erms
... skipped ...
|
|--1.86%--@plt
| |
... skipped ...
| |
| --0.72%--_IO_file_xsputn@@GLIBC_2.2.5
| _IO_fputs
| string_map_dump
| main
| __libc_start_main
| _start
我們能注意到在 textprocessor3.c 裡面的 __memmove_avx_unaligned_erms 跑得很快。一種可能性是因為 strlen 會把等下 memmove 會讀到的資料帶進快取(Cache),所以 memmove 函式幾乎不佔用任何時間。在既有測試資料下,textprocessor4.c 並不能帶來任何改進。如果「值」的字串長度會大於 L3 Cache 的大小,或許 textprocessor4.c 就能展示它的價值。
很多時候效能分析會和程式設計師想得不太一樣。直覺告訴我們指令的數量應該和執行時間成正比。若能減少 CPU 必須執行的指令,總執行時間應該會同步縮減。然而現代的計算機結構有很多機制能幫我們隱藏 Latency(延遲),如果我們最佳化的程式碼不在 Critical Path(關鍵路徑)上,總執行時間是不會有變化的。這再次提醒我們以系統化的方法分析程式效能的重要性。
扣除 strlen 函式之後,在不改動資料結構的前提下,已經沒有多少簡單的最佳化了。所以本節就在此告一個段落。當然這個程式一定還有不少改進空間。例如,我沒有嘗試紅黑樹、雜湊表等等比較複雜的資料結構。其次,gen_test_data.py 產生的測試資料非常固定。如果要更完整地測試程式效能,應該要產生不同長度的字串。這些就留給各位讀者練習。
小結:本節以一個簡單的文字處理程式展示程式效能的分析方法與兩種 Call Graph 的判讀方法。除此之外,也展示了一些平常分析程式時會遇到的狀況。最後,以一個「沒有用的最佳化」結尾。雖然這樣的結果可能會令人感到挫折,不過這就是效能分析工程師的日常生活。一個方法不成功,就分析為什麼不成功,之後建立假說、實驗、再改進方法。
結語
本文從Call Graph 的原理談起,接著再介紹記錄 Stack Trace 的注意事項與Call Graph 的判讀方法。最後本文以一個實際的例子示範如何使用 Perf Events 分析與最佳化程式。
希望這篇文章能對各位讀者的工作有所助益。如果文章有任何錯誤,也請不吝指教。
系列文章
- 使用 perf_events 分析程式效能
- 簡介 perf_events 與 Call Graph(本文)
參考資料
- perf-report(1) Manual Page
- Brendan Gregg, perf Examples
- Brendan Gregg, Flame Graphs
- Andi Kleen, (2016). An introduction to last branch records, LWN.net
- Intel 64 and IA-32 Architectures Software Developer's Manual, Volume 3 Section 17.11 Last Branch, Call Stack, Interrupt, and Exception Recording for Processors Based on Haswell Microarchitecture
- Linux Kernel, tools/perf/util/machine.c,
resolve_lbr_callchain_sample() - Debian Bug #767756: glibc: Consider providing a libc build compiled with -fno-omit-frame-pointer to help with profiling
Note
如果你喜歡這篇文章,請追蹤羅根學習筆記粉絲專頁。最新文章都會在粉絲專頁發佈通知。




